AnimeTransGAN: Animation Image Super-Resolution Transformer via Deep Generative Adversarial Network
Introduction
Classic animation content often lacks the resolution and visual detail needed for modern high-definition displays, such as UHDTV. Existing super-resolution (SR) methods struggle with animation-specific challenges—GAN-based models may miss fine details, while transformer-based models can introduce visual artifacts.
This work addresses the task of animation image super-resolution by proposing a novel deep learning framework, AnimeTransGAN, which combines the strengths of both GANs and transformers. The goal is to generate high-quality, visually appealing high-resolution animation images that preserve artistic style and fine details.
Research Purpose
To overcome the limitations of current methodologies—where GAN-based models often fail to recover fine image details and transformer-based models may introduce artifacts such as over-blurring or over-sharpening—this work proposes AnimeTransGAN, a novel deep learning architecture that:
- Utilizes the superior detail restoration capabilities of transformer networks.
- Employs a U-Net-based discriminator to improve the realism and perceptual quality of the generated images through adversarial training.
Proposed Architecture

Performance Evaluation
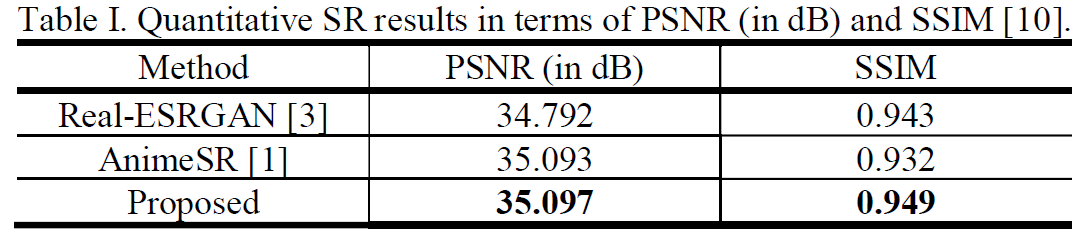
SR Result Comparision
